ML-Based Video Compression
Using autoencoders to compress video frames efficiently with minimal quality loss
Project Overview
This project demonstrates how neural networks can be used for video compression tasks. By training an autoencoder model to compress video frames into a low-dimensional latent space and reconstruct them with minimal loss, we can achieve competitive compression results compared to traditional codecs like H.264.
The project showcases an important application of machine learning in multimedia processing, with potential applications in video streaming, storage, and transmission for mobile devices.
Key Highlights
- Neural compression of video frames
- Quantized latent space representation
- Comparison with H.264 codec
- Quality evaluation (PSNR, SSIM)
- Interactive visualizations
Technical Approach
The project is implemented in four stages, each building on the previous:
Stage 1: Frame Extraction
Extracting individual frames from source videos using OpenCV to prepare data for neural compression.
# Example frame extraction
frames = extract_frames("input_video.mp4", "extracted_frames", interval=1)Stage 2: Autoencoder Construction
Building and training a neural network with encoder, quantizer, and decoder components.
# Autoencoder architecture
model = VideoAutoencoder(latent_dim=64, num_bits=8)
# Train model
model = train_autoencoder(model, dataloader, num_epochs=5)Stage 3: Compression Evaluation
Comparing our neural compression against traditional H.264 using objective quality metrics.
# Evaluate compression methods
autoencoder_results = evaluate_autoencoder(model, dataloader, device)
h264_results = evaluate_h264(frames_dir, crf=23)Stage 4: Results Visualization
Generating comprehensive visual reports to analyze compression performance.
# Create visualizations
visualizer = VideoComparisonVisualizer(original_frames, ae_frames, h264_frames)
visualizer.generate_summary_report()Neural Network Architecture
Encoder
- 5 convolutional layers with stride-2
- ReLU activations and batch normalization
- Reduces 256×256×3 image to 8×8×64 representation
- Progressive feature extraction from pixels to high-level features
Decoder
- 5 transposed convolutional layers
- Mirror image of the encoder architecture
- Sigmoid activation for final output layer
- Reconstructs original image from latent representation
Quantizer
The quantizer module simulates real-world bit constraints by reducing the precision of the latent representation. It uses a straight-through estimator technique to allow gradient flow during training, despite the non-differentiable quantization operation.
Results
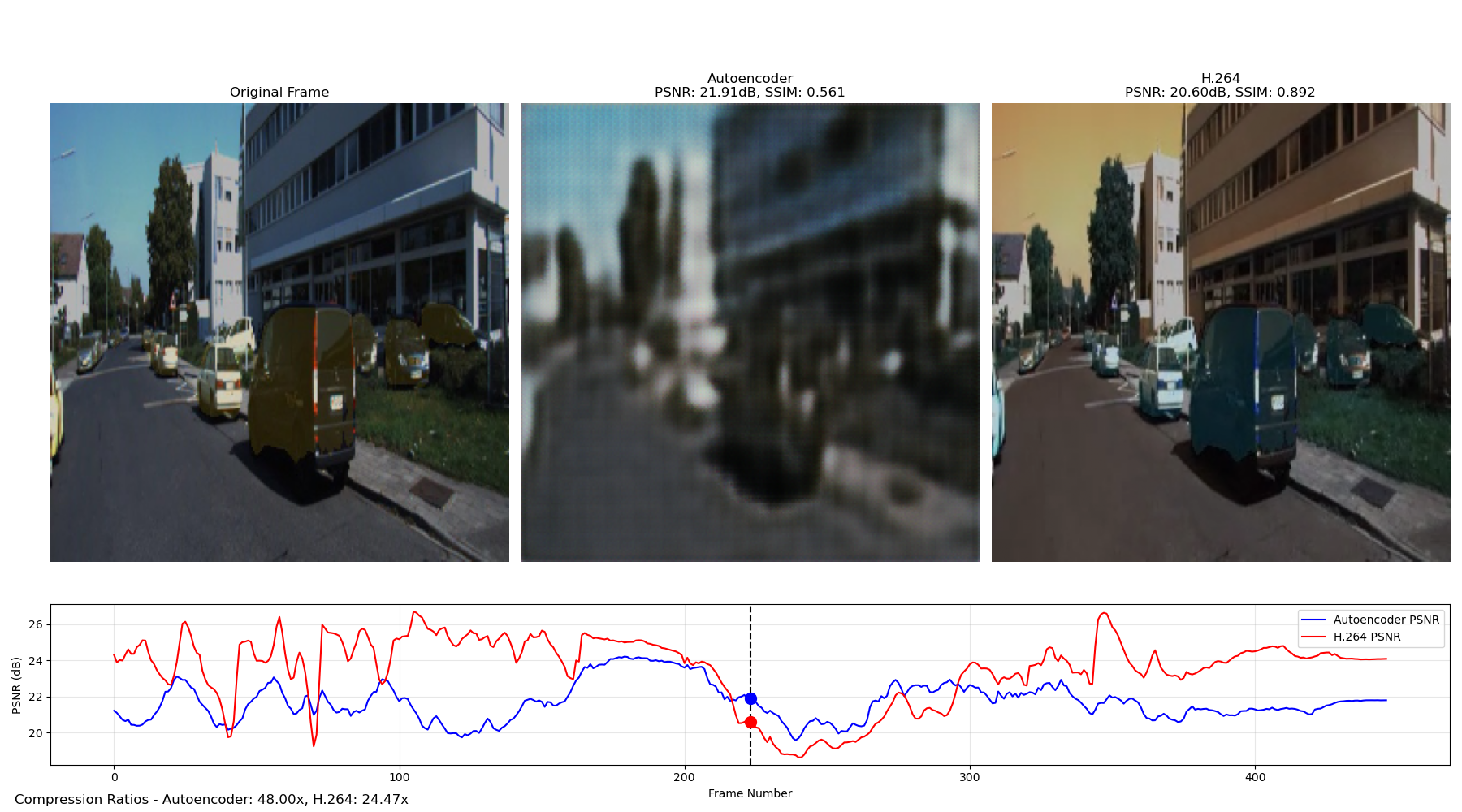
Side-by-side comparison of original (left), autoencoder (middle), and H.264 (right) compressed frames
Quality Metrics
| Metric | Autoencoder | H.264 |
|---|---|---|
| Average PSNR | 21.71 dB | 23.52 dB |
| Average SSIM | 0.5373 | 0.8966 |
| Min PSNR | 19.58 dB | 18.63 dB |
| Min SSIM | 0.4353 | 0.8451 |
| Max PSNR | 24.21 dB | 26.69 dB |
| Max SSIM | 0.6296 | 0.9264 |
| Compression Ratio | 48:1 | 24.47:1 |
Key Findings
- Compression Efficiency: Our neural approach achieves nearly double the compression ratio (48:1) compared to H.264 (24.47:1), demonstrating the potential of learned compression techniques.
- Quality Trade-offs: The autoencoder sacrifices some visual quality (lower PSNR and SSIM) to achieve higher compression rates, highlighting the fundamental trade-off in compression systems.
- Consistency Patterns: The autoencoder shows more consistent performance across frames with less dramatic quality fluctuations, while H.264 exhibits higher peaks and lower valleys in quality metrics.
- Future Potential: Despite lower quality metrics in this implementation, the neural approach demonstrates promising compression efficiency that could be improved with more sophisticated architectures and training techniques.
Metrics Over Time
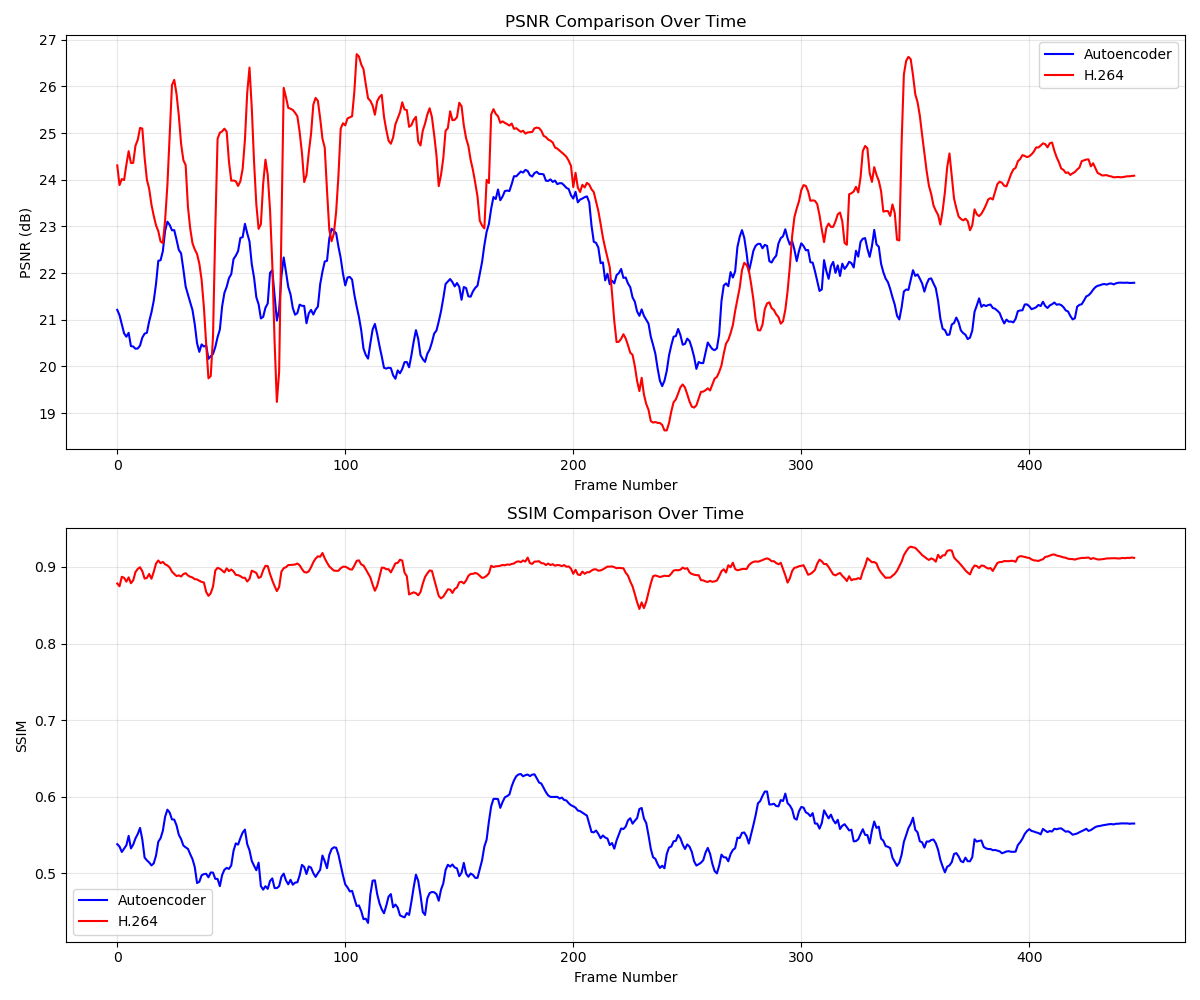
PSNR and SSIM metrics across video frames
Metrics Distribution
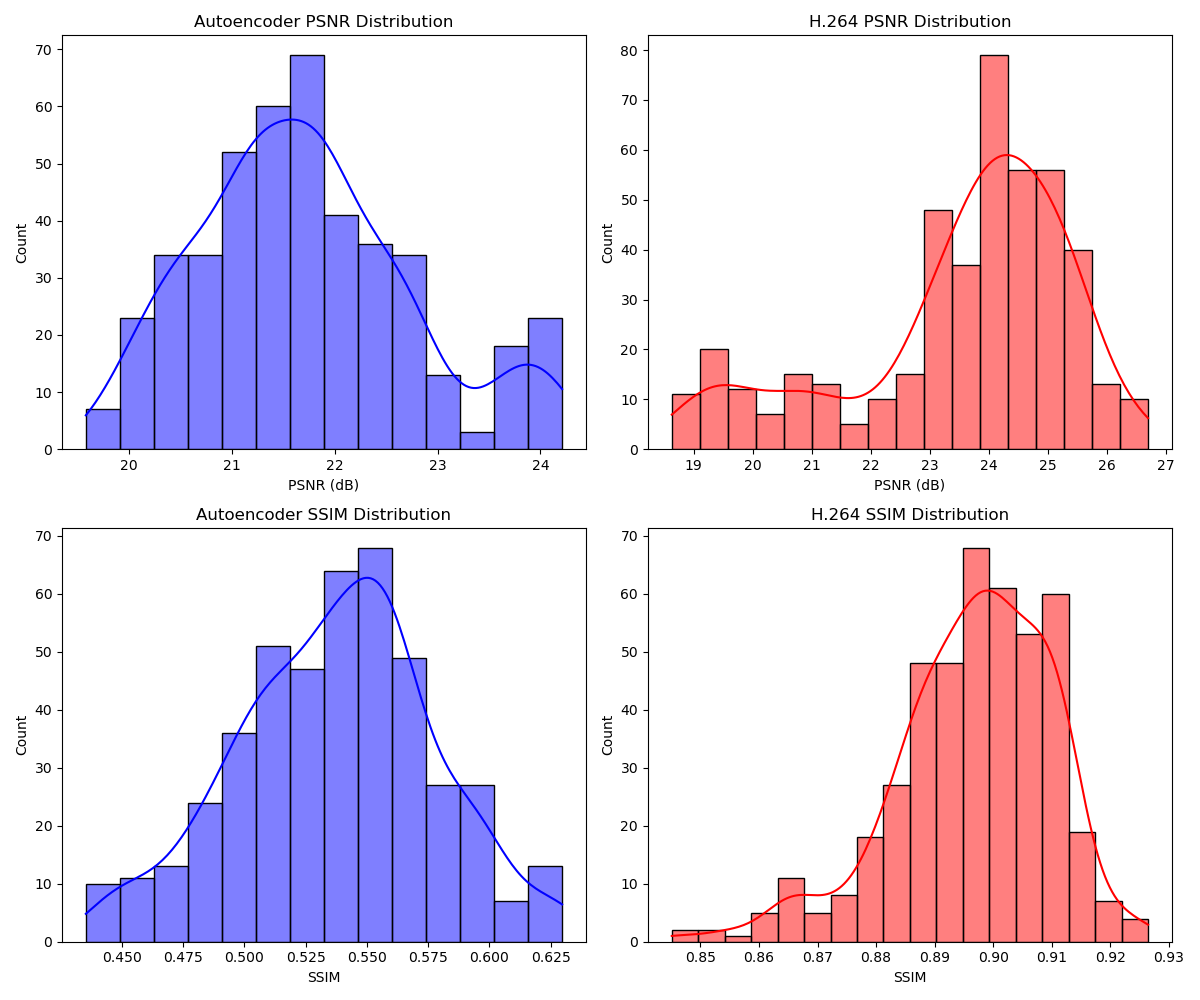
Distribution of PSNR and SSIM values for both compression methods
Using the Code
To run this project yourself, follow these steps:
# 1. Clone the repository
git clone https://github.com/NiharP31/ML_ViC.git
cd ml-video-compression
# 2. Install dependencies
pip install -r requirements.txt
# 3. Run the complete pipeline
python extract_frames.py --video input_video.mp4 --output extracted_frames
python frame_autoencoder.py --frames extracted_frames --epochs 10
python compression_evaluation.py
python results_visualization.pyThe visualization results will be saved in the visualization_results directory, including comparison images, metrics reports, and the side-by-side video.